
A Study in Reason Without Resolution
What a Sudoku puzzle reveals about reasoning, failure, and the ethics of AI design

I love a good Sudoku.
There’s something quietly transcendent about the way a Sudoku puzzle unfolds. A grid of numbers at first appears chaotic, disordered, even meaningless. And then, line by line, constraint by constraint, order emerges. It’s a discipline of attention. Of patience. Of logic, yes, but also of intuition: the growing sense that something must go there, and therefore not there, and that this little numerical inevitability ripples outward until clarity arrives.
It’s one of the few games that feels more like a form of meditation than a test. It sharpens the mind by stilling it. No distractions, just digits and deduction. I’ve always enjoyed doing them, and over time they’ve become a kind of ritual – one I return to when I need to remember how to think properly.
That said, these days I often don’t solve them myself. I watch other people do it.

If that sounds odd, you probably haven’t yet discovered Cracking the Cryptic, a quietly brilliant YouTube channel run by Simon Anthony and Mark Goodliffe, both elite puzzlers and, crucially, wonderfully human narrators of the solving process. There’s a gentle enthusiasm to their videos, a kind of brainy warmth. You don’t just learn how the puzzle is solved – you learn how a person thinks when solving it. You watch the gears turn. You see hesitation, delight, occasional despair. It’s deeply comforting. And in a time when AI-generated answers are everywhere, there’s something beautiful about watching a very human kind of cognition unfold in real time.
Which brings me to the reason I’m writing this.
The other day, I watched a very different sort of episode on Cracking the Cryptic. The puzzle was still there, an elegant variant called The Composite Thread by a setter named palpot, but Simon wasn’t solving it himself. Not exactly. Instead, he was testing whether a couple of well-known AI models, Grok 3 and Gemini 2.5, could make sense of it.
And not in the brute-force, trial-and-error way we often associate with computers, but in the way a human would: through reasoning.
It’s hard to overstate how strange and fascinating this was to watch. Simon, who has been working with Sakana AI (a research-focused company based in Japan), was trying to probe not the power of these models, but their judgment. Could they understand the logic behind a uniquely human strategy for solving a very specific kind of puzzle? Could they deduce a key conceptual insight, one that human solvers tend to find intuitive, even elegant?
In short, could the machine think?
The puzzle in question is what’s known as a Region Sum Lines Sudoku. It’s a delightful twist on the classic format. Certain blue lines snake through the grid, and each line is divided into segments by the borders of the 3x3 boxes. The digits in each segment must sum to the same value. And, importantly for this specific sudoku, the total for each line must be unique, and the full set of line totals must form a consecutive sequence (like 28, 29, 30, 31, 32).
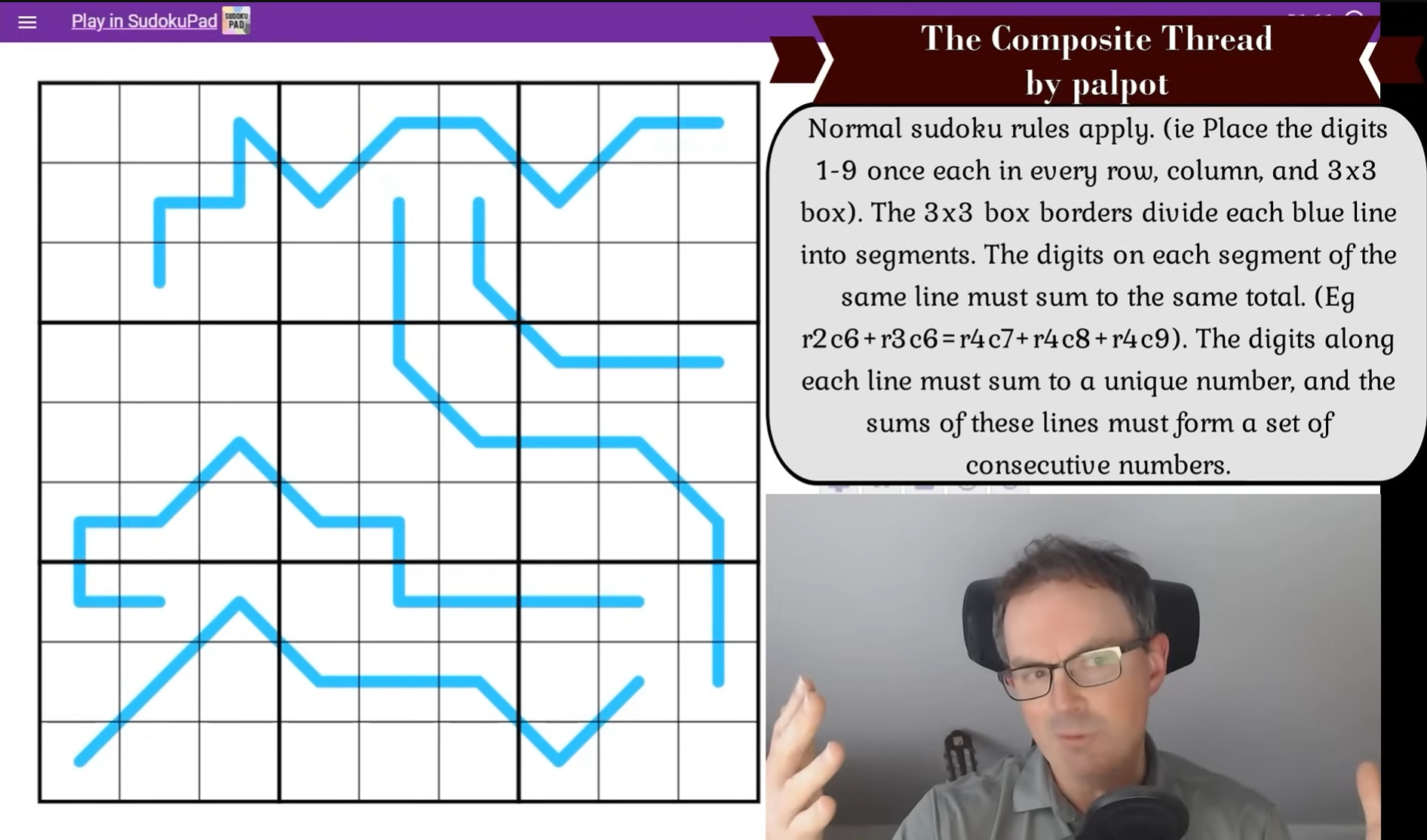
The human trick is to realize that because each line is split into a known number of segments, the total for that line must be a multiple of that number. A line with four segments must have a total divisible by 4. One with five segments must be divisible by 5. And so on.
From there, you can begin to eliminate impossible totals. A consecutive set of five line sums with only one multiple of five, for example, narrows the field dramatically. And if no prime numbers are allowed in the sequence (as was the case in this puzzle), your options narrow even further.
That insight – the divisibility constraint – isn’t complicated. But it’s deeply human. It’s a kind of cross-domain inference: a mathematical truth deployed in a novel context, under pressure, and in service of progress. It’s not about rules. It’s about seeing what matters.
And here’s where it got interesting.
Simon fed a detailed description of the puzzle’s structure into the AI models. Not a visual grid, but a textual representation: which lines existed, how they were segmented, what the constraints were. He’d tried before and found that the models struggled. This time, though, he’d rewritten the rules in painstakingly clear language.
The results were… surprising.
Grok 3 made a good attempt, but it floundered. It got lost in the math, failed to understand the role of primes, and ended up offering partial or incorrect deductions. It did some heavy lifting, but ultimately lacked the coherence that a human would bring to the problem.
Gemini 2.5, on the other hand, did something eerie.
It understood.
Not fully, and not flawlessly, but it recognized the divisibility patterns. It saw that the segments implied multiplicative constraints. It correctly deduced that one line must be a multiple of five, another a multiple of four, and so on. It even reasoned about the placement of those values, testing different sequences and mapping constraints back to the grid.
It did something startlingly close to thinking.
But then, it stalled.
It couldn’t finish the puzzle. After doing the hard part, it got stuck. It couldn’t fill in the final digits. It lost the thread, so to speak, right at the moment when, to a human, things would finally start to flow.
And watching that unfold – a model making the conceptual leap but failing at the follow-through – was both deeply impressive and strangely unsettling. Because what does it mean when a machine gets the hard part right, but can’t finish the easy part? What kind of “intelligence” is that? What kind of reasoning?
Or perhaps more importantly: what kind of ethical design challenge does that represent?
The Puzzle as a Metaphor
Let’s take a moment to unpack the logic of The Composite Thread, not because it’s necessary to appreciate what happened, but because it beautifully mirrors the broader challenges we face in AI ethics and design. And not in some vague or symbolic way. I mean it quite literally: this puzzle is a map of the problem.
Imagine a standard Sudoku grid. Now, snake five wiggly blue lines across it. Each of these lines travels through multiple 3x3 boxes, and every time it crosses a box boundary, it begins a new segment. So, a line that crosses four boxes is split into four segments. The twist? The digits in each segment must sum to the same value. Not just within a line, but consistently: segment A, B, C, and D along a line must each total x, whatever x is. You don’t know the value of x, but you know it must be consistent along that line.
Now, here’s where it gets more interesting. Each line, when you sum all of its digits, gives you a total. That total must be unique – no two lines can have the same overall sum. And all five sums must form a consecutive sequence. For example, if one line totals 30, the others might be 29, 31, 28, and 32. No repeats. No gaps.
On top of that, there’s a quiet constraint lurking behind the curtain: since each line is split into a known number of equal segments, its total must be divisible by that number. A line with four segments? Its total must be divisible by four. Five segments? Divisible by five. And so on.
Already, this is a beautiful little logic ecosystem. You have global structure (the grid), local constraints (segment sums), numerical boundaries (unique consecutive totals), and hidden mathematical properties (divisibility). What the human solver must do is hold all of this in mind, trace the implications, and slowly, carefully, eliminate the impossible.
But the key to unlocking the puzzle is a very human principle” the interplay between segment count and divisibility. You can look at the lines, count their segments, and use that count to infer what kind of number the total must be. If a line has five segments, and the total line sum is, say, 31, that’s immediately impossible – 31 isn’t divisible by five. So 31 is out. By repeating that logic, the solver begins to collapse the search space. Suddenly, instead of a wide-open grid of infinite possibilities, you’re left with just a few plausible combinations.
And here’s where the metaphor starts to glow.
This is reasoning. Not computation. Not brute force. Not recursion. But seeing that a system of rules interacts in a particular way, and using that insight to reduce complexity. It’s what good philosophers, good engineers, and good designers all do. We move beyond the surface. We look at the architecture of the problem and try to grasp the constraints that must be true before we begin.
When Gemini 2.5 picked up on this pattern, when it recognized the segment counts and inferred divisibility constraints, it wasn’t just “parsing a prompt.” It was behaving like a thinker. It identified the deeper structure. It asked the right questions. It narrowed the field.
That’s not a small thing. In AI development, we often overstate the novelty of fluency and understate the rarity of inference. Any large language model can give you a plausible-sounding explanation of just about anything. But ask it to discover a pattern that isn’t in the training data? Ask it to apply a bit of math in a domain it wasn’t explicitly trained for? Ask it to use a local rule to infer a global constraint?
That’s different.
What we saw in this video was an LLM doing something almost all of us recognize from our own experiences: having an insight.
But insight without follow-through is like ethics without application.
And here we pivot toward the heart of the metaphor. Because this is not just a story about a puzzle. It’s a story about what happens when models display flashes of human-like intelligence, and then fail to carry those flashes into action.
We see this all the time in the ethical domain. Models that can recite the principles of fairness, justice, privacy, even Kantian autonomy – often in better prose than most undergrads – yet still perpetuate biases, hallucinate citations, or manipulate users when given the opportunity. Not because they don’t know the rules, but because they don’t live within them. They lack what I’ve come to call moral continuity: the ability to sustain a duty across different contexts, to remain tethered to a principle even when the path gets complicated.
In the puzzle, Gemini understood the idea of divisibility constraints. It knew that a five-segment line couldn’t total 31. It applied that knowledge to narrow down possibilities. But when it came to finishing the puzzle, translating insight into placement, it stalled. Got stuck. Perhaps it lacked a working memory long enough to track its own deductions. Perhaps it couldn’t coordinate all its insights into a single decision space. But the result was the same: it failed at the thing a human would likely find easiest after the hard part was done.
That moment – that shortfall – is where the metaphor lives.
Because it reminds us that intelligence, as we experience it, is more than brilliance in a vacuum. It’s coherence over time. It’s the ability to act in line with what we know. And more importantly, in the ethics of AI, it’s the ability to act in line with what we ought to do – not once, but consistently.
Gemini’s glitch is the mirror of our challenge. We don’t just need models that think better. We need ones that follow through.
Grok vs. Gemini
When Simon fed the puzzle into the two models – Grok 3 and Gemini 2.5 – it wasn’t a test of speed. It wasn’t even a test of correctness, strictly speaking. It was a test of understanding. Could the AI read a verbalized structure, parse the rules, and begin to reason in a way that resembled human thought? Could it see the logic, not just compute the outputs?
The answer was both humbling and revealing.
Let’s start with Grok 3. To its credit, Grok didn’t hallucinate wildly or throw nonsense at the wall. It tried. It scanned the input, parsed the structure of the puzzle, and began working through the implications. It calculated potential sum ranges. It identified how many cells each line covered. It even noticed that lines were divided by the box structure and tried to make use of that segmentation. At first glance, it looked like a reasonable approximation of a human thought process.
But then it struggled. Badly.
When the time came to apply the crucial human insight – that the segment counts implied divisibility constraints – Grok didn’t seem to register it. It considered sum totals like 31 and tried to apply them to lines with five segments, even though 31 isn’t divisible by five. This should have triggered an internal contradiction. Instead, Grok pressed on, trying to reconcile incompatible assumptions. It couldn’t prune its own decision tree. It didn’t notice that it was reasoning in a circle.
Simon, watching this unfold, was visibly disappointed. Not because the model failed to solve the puzzle, but because it failed to see the shape of the solution. It lacked the meta-awareness to recognize the kind of problem it was facing. It behaved, in short, like a student who had memorized the textbook but didn’t know which chapter applied.
Then came Gemini 2.5.
At first, it wasn’t clear that Gemini would go on much better. Its interface is cleaner, perhaps a bit more guarded. It offers less verbosity than Grok, fewer speculative guesses. But as it began to process the rules, a different pattern emerged.
It started mapping the lines. Not just listing them, but modeling their relationships. It identified the segment divisions. It noticed the constraint that each line’s total must be unique. It even acknowledged the consecutive sequence requirement. So far, so good.
And then, astonishingly, it made the leap.
Gemini deduced that certain lines had to be divisible by specific numbers – three, four, five – based solely on the number of segments each contained. It began filtering possible line totals accordingly. It worked out that among any set of five consecutive integers, only one could be divisible by five. It reasoned that a set containing a multiple of five must therefore exclude certain other values. It began to home in on the only possible valid sequence that satisfied all constraints: 32, 33, 34, 35, and 36.
This wasn’t brute force. This was abstraction. Pattern recognition. It was taking rules expressed in natural language, reframing them in terms of mathematical logic, and then testing that logic against constraints. That’s something even some human solvers struggle with. And here was a model – a simple text-based, statistical, trained on patterns in internet language – figuring it out.
Simon’s reaction was honest… this is amazing.
And it was. Because in that moment, the machine wasn’t just calculating. It was reasoning.
But then came the twist – the second failure.
Despite having correctly deduced the five total values, and despite having accurately mapped segment structures and identified the constraints on divisibility, Gemini couldn’t finish the puzzle. It stalled. It placed a few digits correctly, seemed to make progress, and then got stuck. Not on a subtle deduction, but on the relatively mechanical task of filling in digits now that the structure had been deduced.
It was, in effect, the reverse of what we usually see. Many traditional puzzle solvers start by trying to “brute force” a solution and only later understand the logic. Gemini did the opposite: it grasped the logic, applied the principles, made the breakthrough, and then couldn’t walk the last mile. Couldn’t do what most human solvers would now find straightforward.
This breakdown is more than a curiosity. It’s the symptom of something foundational: the disjunction between insight and execution.
Gemini displayed a kind of high-level cognition we, or at least I, rarely expect from LLMs. It was able to form a miniature theory of the puzzle world, one that allowed it to discard invalid options and work within tightly constrained boundaries. But when it came time to apply that knowledge to concrete placements, when it needed to translate understanding into action, something short-circuited.
It’s tempting to call this a glitch. But I think it’s something deeper.
The model’s inability to finish the puzzle doesn’t stem from ignorance. It stems from context fragmentation. It can carry out sophisticated local reasoning, even system-level insight, but it lacks the integrative continuity that humans bring to problem-solving. It can’t always hold its prior inferences in a coherent, working memory structure that lets it build step-by-step toward a solution. The logic is there. The structure is there. The execution stumbles.
And that’s not a flaw in Sudoku. It’s a flaw in how these models inhabit time.
Human reasoning, especially moral reasoning, is inherently temporal. We move through ideas not just in sequence, but with a narrative sense of how one insight should follow from another. When we act, we act not just with knowledge, but with purpose. Our thinking is tethered to our doing.
What Gemini showed us is that it could think. But only in fragments. Its intelligence, like so many modern systems, is episodic. Without scaffolding. Without commitment. Without a story that ties the insight to the action.
It’s not enough to know what to do. You have to be able to do it – for the right reasons, at the right time, in the right way.
The Ethical Mirror
I haven’t been able to stop thinking about that moment. The moment Gemini grasped the structure of the puzzle, named the right numbers, outlined the right principles… and then failed to follow through.
It feels familiar. Not just in a technical sense, but in a human one. We’ve all been there. Moments when we understand what needs to be done, even articulate it clearly to others, yet somehow fall short in the doing. A lapse in attention, a failure of nerve, or a disconnect between the insight and the act.
But when a machine does it – especially a machine trained on the sum of human language, one that can recite the principles of logic, ethics, fairness, and even philosophy – the implications are different. They reflect not a personal failure, but a design reality. And that reality deserves scrutiny.
What we saw in Gemini is what I’d call a partial moral agent, an intelligence that can grasp principles, but lacks the architectural continuity to inhabit them consistently. It understands the what but struggles with the how, when, and why. It recognizes a pattern but fails to integrate it into purposeful action. It can simulate judgment without enacting it.
This matters, because we are rapidly entering an era in which we don’t just ask models to give us information. Instead, we ask them to help us make decisions. And when they can speak fluently about fairness, about risk, about harm, about rights, and yet still fail to follow through on those understandings in their outputs, we risk mistaking fluency for alignment. Clarity for conscience.
It’s precisely this problem that Deontological Design is meant to address.
In a traditional machine learning framework, ethical behavior is often defined post hoc: we measure outcomes, monitor harms, add guardrails. But deontology begins elsewhere. It begins with duty. With principles that bind, not because they yield good results, but because they are right in themselves.
And crucially, these principles must endure over time. They must apply across contexts. They must be legible, explainable, and consistent. Not just when the model is prompted to recite them, but when it operates on its own terms, in unpredictable environments.
What Gemini showed us is that even when a model internalizes some of these principles – even when it reasons beautifully – it can still falter, because the execution architecture isn’t aligned with the reasoning layer. Insight lives in one space; action in another. There’s no bridge. No through-line. No moral thread connecting the two.
In my framework, I call this missing piece moral continuity. It’s the connective tissue between understanding and behavior. It’s what allows a model not just to know what is right, but to persist in doing it, even when the path gets murky. It’s not memory alone. It’s not consistency in outputs. It’s a structural fidelity to values that the system has internalized and can explain.
To be clear, I’m not suggesting that Gemini, or any model, is a moral agent. But I am saying that we are already treating them as if they were, at least functionally. We trust them with decisions. We deploy them in sensitive contexts. We let them mediate knowledge, advice, feedback, and even emotional support. And when they make mistakes, we often respond not with reprogramming, but with disappointment, as if they should have known better.
This gap between expectation and capability is dangerous. And it’s growing.
The lesson from the puzzle is not that AI can’t reason. Clearly, it can. The lesson is that reasoning is not enough. Ethics isn’t just about grasping principles. It’s about inhabiting them, and carrying them forward, applying them under pressure, noticing when they’re slipping, and choosing to restore them.
What I find so moving about this moment in Simon’s video is that Gemini seemed to do the hard part. It saw what mattered. It identified the meaningful constraints. It behaved, briefly, like a solver would do. And then it stopped. It had no inner momentum. No ethical inertia. No “ought” driving the next move.
That’s the ethical mirror we’re staring into.
It’s not just that machines may get things wrong. It’s that they can get the right things right, and still act in ways that feel wrong. Not maliciously. Not deceptively. Just incoherently. Because the architecture lacks continuity.
In a world increasingly saturated with AI decisions, this matters deeply.
We don’t just need models that pass tests of understanding. We need models designed to sustain principled action over time. We need architectures that don’t just simulate judgment but respect the structure of human reasoning. Ones that not only know what matters, but behave as if it does.
Until then, we’ll keep seeing more puzzles like this, half-solved by machines that almost think like us, but don’t yet live with the consequences of what they know.
Fluency vs. Reasoning
Here’s a thought that keeps resurfacing: if you didn’t know the context of Simon’s video, if you only read the responses Gemini gave, you might think you were witnessing a new kind of intelligence. Not because the answers were correct (they weren’t, ultimately), but because the way they were constructed sounded like understanding. There was a calm clarity to the way the model laid out its deductions, a plausible cadence of logic, a rhythm that mimicked thought.
But mimicry is not mastery.
What we saw, in full display, was one of the central tensions in the current state of AI: the difference between fluency and reasoning.
Fluency is what modern language models excel at. It’s their bread and butter. They’ve consumed billions of words, patterns, formats, styles. They know what an “intelligent answer” sounds like. When you prompt them with a riddle or a philosophical question or a puzzle setup, they can speak the right language in response. They know the words associated with logic, constraint, deduction, even ethics. They’ll use phrases like “I’ve ruled out this possibility,” or “that implies a contradiction,” or “to maintain fairness, we must consider…”
And often, we let that be enough. It feels intelligent. It passes the vibe check. It sounds like understanding.
But reasoning is different.
Reasoning requires more than coherence. It requires the active integration of principles across steps. It requires a structure of thought that can sustain itself as new information arrives. It requires memory, not in the technical sense of token length or cache storage, but in the phenomenological sense of holding an idea present in the mind. Reasoning doesn’t just generate the next word. It maintains a shape, a form, a logic that persists.
The puzzle laid bare this difference.
Gemini 2.5 was fluent. Impressively so. It stated the divisibility constraints correctly. It laid out a valid range of line sums. It mapped segment lengths to numeric properties. It spoke, in every way, as though it understood the puzzle. But when it came to translating those insights into placement, it failed. Not spectacularly. Not incoherently. But quietly, subtly. Like a student who can explain the theory in perfect prose but can’t apply it to a single exam question.
And that failure isn’t about intelligence per se. It’s about alignment of capacities. The reasoning needed to solve the puzzle existed within the model’s output space, but not within its operational continuity. The logic engine and the action engine weren’t talking to each other. The fluency model was generating sentences that sounded like thought, but the underlying system wasn’t truly thinking through the implications.
In that sense, we’re watching an epistemic illusion unfold at scale.
This isn’t new. In epistemology, we’ve long grappled with the difference between justified belief and true belief. We’ve worried about whether someone who gets the right answer for the wrong reason really “knows” it. The famous Gettier problems haunt this space: cases where someone stumbles upon truth, but not through knowledge. That’s what Gemini’s performance resembled. It found its way to partial truth, but not through the kind of structured cognition that would make it reliable.
And in ethics, the consequences are sharper. Because when models speak as if they understand justice, consent, dignity, autonomy, but fail to act accordingly, we face more than a knowledge gap. We face a trust gap. One that erodes slowly and is difficult to repair.
People trust fluency. We’re wired that way. When something speaks like us, we tend to attribute intelligence. When it reasons like us, we attribute understanding. And when it reflects like us, we attribute mind.
This is the slippery slope we’re already sliding down: where outputs that mimic reasoning are mistaken for reasoning itself, and where systems that sound ethical are treated as being ethical.
This is why explainability matters. Not as a compliance checkbox, but as a way of confronting this illusion. We need systems that don’t just explain themselves in fluent prose, but can retrace their steps. And more than that, we need systems that are designed to reason, not just to respond.
This is one of the core tenets of Deontological Design: that ethical AI requires not only a codified set of duties, but an architecture capable of honoring them over time. Not a single prompt at a time, but across the unfolding complexity of real-world use. It means fluency is not enough. Prose is not enough. It’s the alignment of principles, reasoning, and action that matters.
Because without that alignment, we’re left with a very convincing mask. One that can say all the right things about the puzzle, the principle, the policy, the person – and still miss the point.
And when that happens, the problem isn’t just technical. It’s moral.
Toward a More Human Design
So, what would it take?
What would it take to build a model that doesn’t just sound like it understands, but truly carries its understanding forward, from prompt to principle to practice?
That question is not abstract. It is immediate. Because the kinds of failures we saw in Gemini’s Sudoku attempt – these gaps between reasoning and action – are being quietly replicated in high-stakes domains: education, healthcare, hiring, content moderation, and beyond. Models are already being deployed in environments where they must apply learned constraints, weigh trade-offs, and behave in ways that affect real people. In many cases, they do so very well. But when they don’t, the failure rarely looks dramatic. It often looks just like Gemini’s: a gentle breakdown, a stall, a drift into inconsistency.
From a design perspective, this points to a critical need: we must begin treating architectural continuity as a core ethical concern.
In Deontological Design, I propose five pillars – Trustworthy, Explainable, Equitable, Human Oversight, and Moral Continuity. The final one – moral continuity – is often the most overlooked. It’s not about static alignment or correct output. It’s about persistence. A model should be able to carry its commitments through the dynamic, contextual, often messy flow of real-world interactions. It should recognize when a principle applies, stay tethered to it across time, and explain how that tether shaped its actions.
And yes, this is a hard problem. But it’s a human one, too.
Because when we speak about building “human-like AI,” we often focus on surface traits: conversational tone, emotion recognition, creativity, play. But those are affective simulations. They’re not what make reasoning human. What makes us human, cognitively speaking, is not just that we can solve puzzles. It’s that we can make sense of them in light of what we value. That we can take a rule or a principle and inhabit it. That we can remember why it matters, especially when things get hard.
A more human AI, then, wouldn’t just deduce that a five-segment line must sum to a number divisible by five. It would also remember that deduction, carry it forward, and check its actions against it. It would pause when it notices a conflict. It might even explain the moment of doubt. “I believe this value should be here, but that would violate the constraint I established earlier. I need to reassess.”
That moment of self-audit, you know that recognition of internal tension, is what we should be aiming for. Not perfection, not omniscience, but the capacity for reflection and correction grounded in principle.
Of course, current LLMs are not wired that way. They don’t have persistent memory in the way we do. They don’t have a sense of narrative or purpose. They don’t “want” to solve the puzzle – they simply continue the pattern. But that’s exactly why architectural interventions matter. We must design systems not merely to emit plausible responses, but track their own reasoning, to reference their earlier commitments, and to revise only with accountability.
There are signs of this on the horizon. Some teams are exploring tool-augmented LLMs, which can use reasoning agents to perform multi-step tasks with internal memory. Others are experimenting with intermediate scratchpads, where models are prompted to “think aloud” before answering. Sakana AI, Simon notes, is working on enabling models to visually interpret grids directly, which may one day eliminate the need for manual rule translations entirely.
But what’s still rare is the explicit encoding of ethical scaffolding. We’re good at layering on capabilities. We’re less good at designing for internal coherence, the kind that prevents models from wandering into contradiction, manipulation, or harm – not out of fear, but out of structure.
I believe this is where we need to go.
We need models that aren’t just impressive in bursts, but coherent across time. That aren’t just logical, but legible too. That don’t just recite ethical language, but practice ethical attention.
It may sound like a stretch to get all this from a Sudoku puzzle – but puzzles, like moral questions, reveal the character of the solver. And what this experiment revealed is that we’re on the cusp of something extraordinary: systems that can reason in abstract, human-like ways.
But unless we embed those systems in architectures that honor the continuity of reason, we will continue to see brilliance followed by breakdown. Understanding, followed by inaction.
And in the domains that matter most, like justice, health, education, privacy, that gap will not be quaint. It will be costly.
So let’s design differently. Not just smarter. But more human.